---
title: INFO001 (8a) Introduction à l'apprentissage par réseaux de neurones
type: slide
slideOptions:
transition: slide
progress: true
slideNumber: true
---
# Introduction à l'apprentissage par réseaux de neurones
## (Traitement et Analyse d'Image 8a)
>
> [name=Jacques-Olivier Lachaud][time=Decembre 2020][color=#907bf7] Laboratoire de Mathématiques, Université Savoie Mont Blanc
> (Les images peuvent être soumises à des droits d'auteur. Elles sont utilisées ici exclusivement dans un but pédagogique)
###### tags: `info001`
*(Most illustrations taken from S. Prince, Understanding Deep Learning, 2025)*
---
## Types d'apprentissage

---
## Apprentissage supervisé
:::info
**Objectif** le réseau apprend à la corrélation entre des données en entrée et en sortie et prédit les sorties pour de nouvelles données
:::
* régression ou approximation (mono- ou multi-valuée)
* classification (binaire ou multi-classe)
---
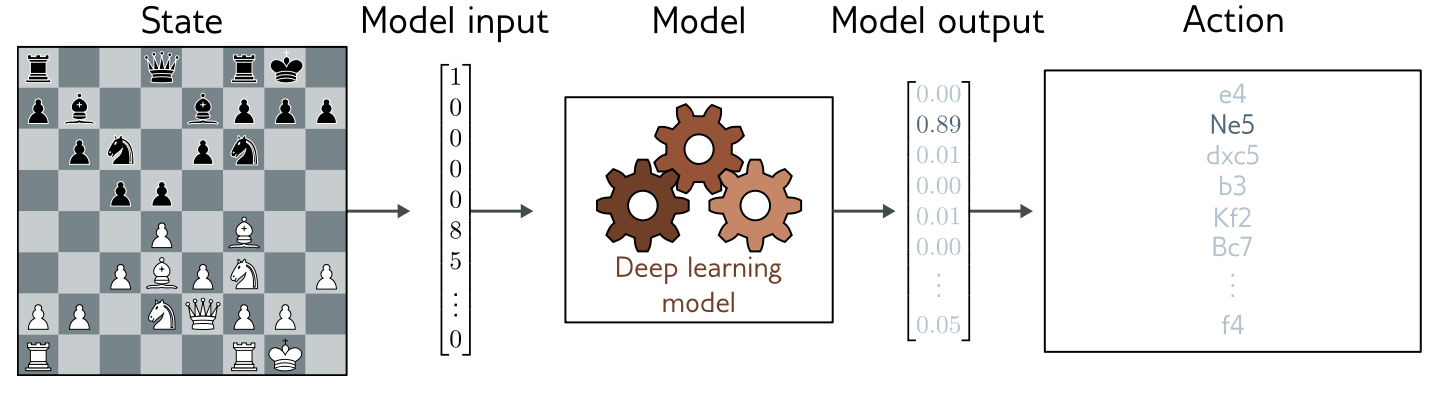
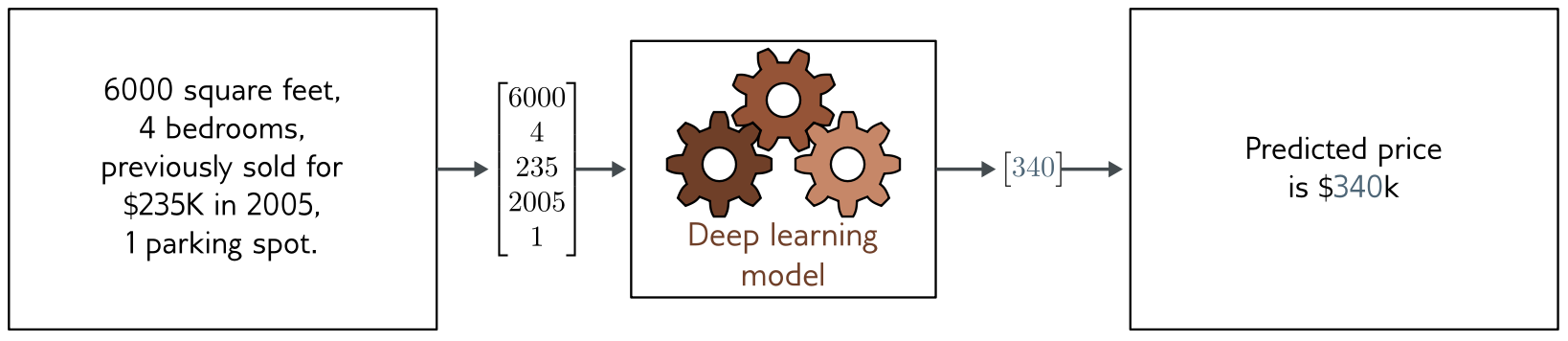
## Apprentissage supervisé: régression ou approximation
|  |
| ------------------------------------------------------------------------------------------------------ |
|  |
|  |
---
## Apprentissage supervisé (approximation)
1. **régression** ou **approximation** (mono ou multi-valué)
* *données*: entrées $(\mathbf{x}_i)$ associées à des sorties $(\mathbf{y}_i)$
* *réseau*: modèle $\mathbf{f}(\mathbf{x},\mathbf{p})$ paramétré par $\mathbf{p}$ (inconnu)
* *objectif*: fonction de perte (loss) $L$
* *entrainement*: trouver $\mathbf{p}$ qui minimise $\sum_i L(\mathbf{f}(\mathbf{x}_i,\mathbf{p}),\mathbf{y}_i, \mathbf{p})$
* *validation*: vérifier que $L$ est aussi petit sur d'autres données.
2. ==Exemple== le modèle **linéaire** (ou *affine*) par **moindres carrés**
* $(\mathbf{x}_i,\mathbf{y}_i)=(x_i,y_i)$, $\mathbf{p}=(a,b)$, $f(x,\mathbf{p})=ax+b$,
* loss $L:=\sum_i (y_i-f(x,(a,b))^2=\sum_i (y_i-(ax_i+b))^2$
* autre exemple $L:=a^2+b^2 + \sum_i (y_i-(ax_i+b))^2$
---
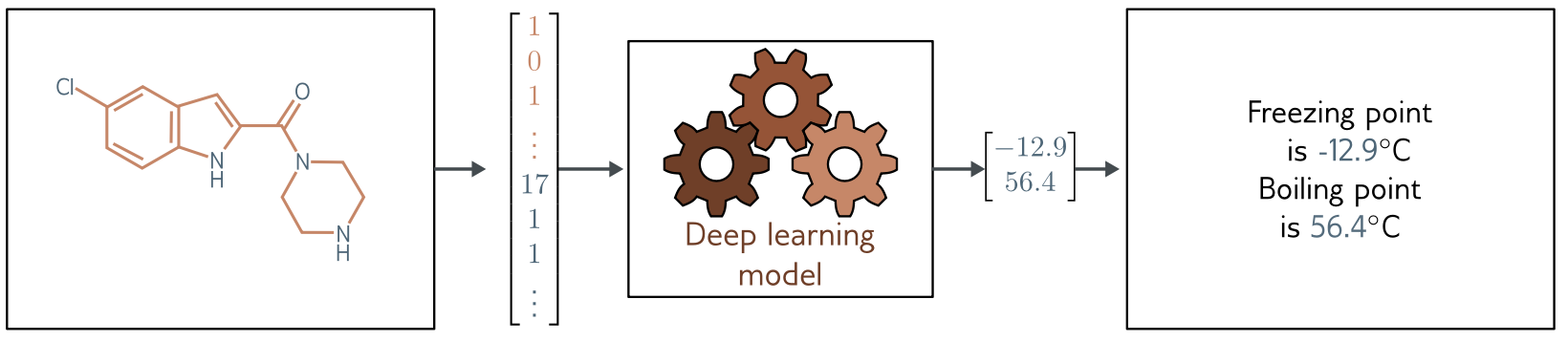
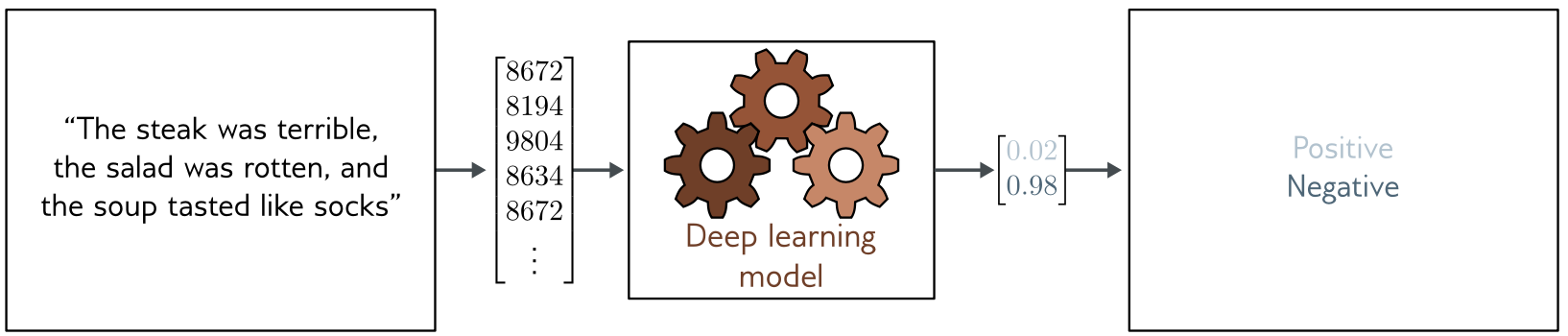
## Apprentissage supervisé: classification
|  |
| ------------------------------------------------------------------------------------------------------ |
|  |
|  |
---
## Apprentissage supervisé: classification (suite)
|  |
| ------------------------------------------------------------------------------------------------------ |
| 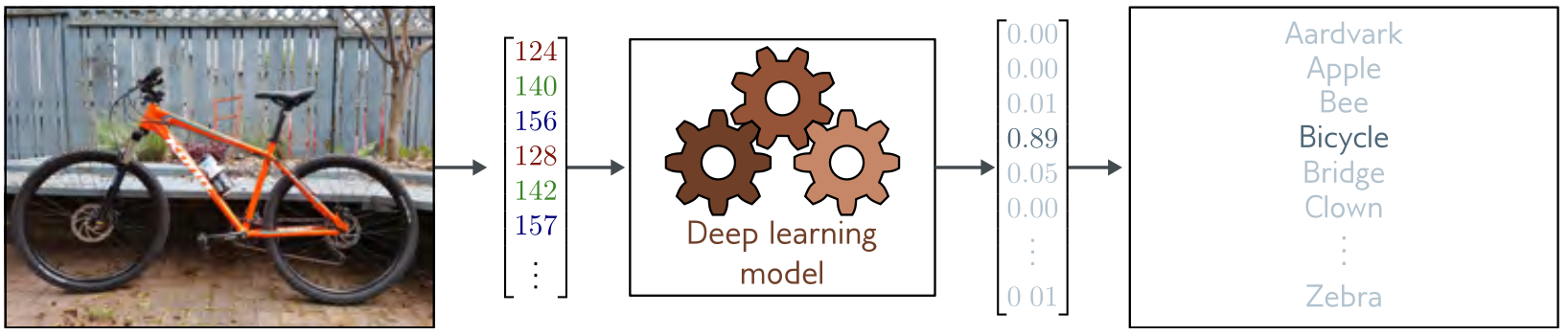 |
---
## Apprentissage supervisé (classification)
1. **classification** (binaire ou multi-classes)
* *données*: entrées $(\mathbf{x}_i)$ associées à des sorties $(\mathbf{y}_i)$
* *réseau*: modèle $\mathbf{f}(\mathbf{x},\mathbf{p})$ paramétré par $\mathbf{p}$ (inconnu)
* *objectif*: fonction de perte (loss) $L$ via **maximum de vraissemblance**
* *entrainement*: trouver $\mathbf{\phi}$ qui minimise $\sum_i L(\mathbf{f}(\mathbf{x}_i,\mathbf{p}),\mathbf{y}_i, \mathbf{p})$
* *validation*: vérifier que $L$ est aussi petit sur d'autres données.
2. ==Exemple== la classification binaire par **max de vraissemblance**
* $(\mathbf{x}_i,\mathbf{y}_i)=(x_i,y_i)$, $y_i$ vaut 0 ou 1, $\mathrm{sig}(z)=1/(1+e^{-z})$
* loss (moindres) $L:=-\sum_i \log(Pr[y_i|\mathbf{f}(x_i,p)])$
* $L:= \sum_i −(1 − y_i) \log(1 − \mathrm{sig}[f(x_i, \mathbf{p})]) − y_i \log \mathrm{sig}[f(x_i, \mathbf{p})]$
* le réseau prédit une distribution de probabilités
---
## Entrées
* très variables en taille (quelques nombres à des millions pour une image)
* l'ordre des données peut ne pas être important
* ... ou être essentiel (texte, son, image)
* transformées en vecteurs de nombres à virgule flottante
* **choix** des données et la **qualité** des données essentiels
---
## Sorties
* elles sont souvent **structurées**:
* l'ordre des mots dans un texte
* la segmentation d'une image est superposée à l'image d'entrée
* une traduction d'un texte dépend d'une grammaire
* une image générée a ses pixels dans un ordre logique
---
|  |
| ------------------------------------------------------------------------------------------------------ |
|  |
---
## Apprentissage non-supervisé
:::info
**Objectif** le réseau apprend une distribution des données et génère des nouvelles données qui suivent cette loi de distribution.
:::
* modèles génératifs non-supervisés (conditionnels ou non)
* variables latentes (espace de dimension "petite" générant la distribution)
---
## Modèles génératifs (chats, batiments, inpainting)


---
#### DeepAI `African savanah image with animals and labels`

---
### LLM (prediction of plausible text)

---
## espace latent d'un ensemble d'images


---
## espace latent pour de l'interpolation d'images

---
## Apprentissage par renforcement
:::info
**objectif** Trouver une fonction entre les **états** du système et les **actions** à entreprendre. Le réseau apprend par explorations (en général non-déterministe) et reçoit des récompenses en fonction des succès/échecs.
:::