525 views
owned this note
# ecoinfoFAIR 2024 - annotation & gestion de médias
# Carnet de bord
**site web** https://ecoinfofair2024.sciencesconf.org/
**dates et lieu** : 19 - 20 - 21 novembre à la Station d'écologie théorique et expérimentale du CNRS - SETE- de Moulis (Ariège)
**lien visio** https://teams.microsoft.com/l/meetup-join/19%3ameeting_Zjc5MTJlZWQtODMyMC00ZDhiLWJjNDMtNTA0NmZlMThhYWU4%40thread.v2/0?context=%7b%22Tid%22%3a%22d0e03c67-e3f8-40c1-a4c9-42041d74b08e%22%2c%22Oid%22%3a%22b13c3b08-b0d6-48fe-8656-1652de46dbac%22%7d
**programme** https://ecoinfofair2024.sciencesconf.org/resource/page/id/1
## journée 1 : 19 novembre 2024
### Tour de table
- CAUCHOIX Maxime <maxime.cauchoix@sete.cnrs.fr>
- VILLEPREUX Tristan <tristan.villepreux@lis-lab.fr>
- Yvan LE BRAS <yvan.le-bras@mnhn.fr>
- Olivier NORVEZ <olivier.norvez@mnhn.fr>
- Dominique Pelletier <Dominique.Pelletier@ifremer.fr>
- Guillaume Debat <guillaume.debat@terroiko.fr>
- Julien Ricard <julien.ricard@terroiko.fr>
- Simon Chamaillé <simon.chamaille@cefe.cnrs.fr>
- Hugo MAGALDI <hugo.magaldi@mnhn.fr>
- Catherine Borremans <Catherine.Borremans@ifremer.fr>
- "belfedhal a" <belfedhal.a@gmail.com>
- Yves bas <yves.bas@mnhn.fr>
- Pauline GUINET <pauline.guinet1@mnhn.fr>,
- Paul Peyret <paulpeyret@gmail.com>,
- Anais Pessato <anais.pessato@mnhn.fr>
- Kevin Darras <kevin.darras@inrae.fr>
- Camille Desjonquères <desjonqc@univ-grenoble-alpes.fr>
- Dorian Cazau <dorian.cazau@ensta-bretagne.fr>,
- Pierre Bonnet <pierre.bonnet@cirad.fr>,
- Colin VanReeth <cvanreeth@creamontblanc.org>,
- Celia Blondin <celiablondin34@gmail.com>
- Elodie Massol <elodie.massol@univ-tlse3.fr>,
- Remy Edgar <remy.edgar@gmail.com>,
- Laura Schillé <laura.schille@inrae.fr>,
- Sophie Pamerlon <sophie.pamerlon@mnhn.fr>,
- SIMONNOT Josephine <josephine.simonnot@cnrs.fr>,
- HOLLIGER Sabine <sabine.holliger@sete.cnrs.fr>
**Mots prononcés**
- Acoustique
- Image
- IA
- Bases de données
- Annotation
- Segmentation
- Marin
- Impact pêche
- oiseaux
- Comportement
- orthoptères
- Vigie Nature
- Sciences participatives
- orchamps
- Congo
### Présentations :
#### Pres.1: Colin / SPOT
- Sciences participatives / CREA
- **SPOT** : https://spot.creamontblanc.org/apropos/spot
- Regroupement de plusieurs programmes de sc. part.
- Particularité vs données opportunistes : **Fonctionnement par "spot"**.
- Retour immédiat aux utilisateurs
- Aussi possibilité de faire observation opportuniste mais pas mieux que iNaturalist
- 2500 inscrits (FR et proches)
- Web app PHP basé sur GeoNature (module monitoring ou octax) + Discourse pour forum
- To-Do
- Voir pour usage offline ?
- Proposer cadre pour ajout de projet dans SPOT par porteurs
- **Wild Mont Blanc** https://www.zooniverse.org/projects/crea-mont-blanc/wild-mont-blanc?language=fr
- Zooniverse.org
- UK et USA
- Annotations sons et images
- Tâches : classification / dessin / texte libre
- MegaDetector -> Wild Mont Blanc (photos retirées dès 30 vues) -> Expert (via indice de simpson sur réponse 99% => fiable..)
- En plus
- Grosse communauté active (1 Millions de contributions en 5 semaines. 2,5 millions de contributions / environ 25 000 contributeurs)
- vitesse d'annotation (~10000 images/semaine)
- Workflow très ajustable sans code
- Gratuit
- Forum adossé
- En moins
- Le côté csv un peu crado qui limite les analyses
- review côté zooniverse qui peut limité les projets + annotations images et/ou sons uniquement
- Annotation d'images par camera traps depuis 2017-2018
- Observation + comportement des animaux
##### Questions spot / wild
- Maxime : Comment se gère l'interface entre spot et zoo universes ?
- deux projets non liés
- Yvan : qq limites de zoouniverse => réservé à qq projets (sélection and co), as tu du recul sur ça ?
- oui il y a des étapes de reviewing
- Camille : Quelle communication faite autour du projet pour avoir autant de participations ?
- Zooniverse fait une newsletter au lancement du projet à tous les inscrits (>1Millions). Les utilisateurs passent d'un projet à un autre.
- Maxime : Quantité de travail nécessaire pour être dans zooniverse
- Tu peux te faire un projet dans ton coin pour tester avec qques utilisateurs
- Maxime : combien de temps il faut pour annoter images ? Autres stats sur participation ?
- 10 000 photos annotés en 1 mois / 1 mois et demi.
- Paramétrage prend 2 à 3 jours. Il faut bien gérer le lien entre sources de données et le "workflow" et besoin de faire appel aux images donc besoin de développement. **Les images doivent être accessibles à distance**.
#### Pres.2: Laura : Bird it!
- dans le cadre du projet tree body gards https://tree-bodyguards.hub.inrae.fr/
- Interface utilisateur pour annoter enregistrements audio / chants d'oiseaux. Fait en local et artisanal ;)
- Utilisation d'une interface existante faite par communauté imagerie radio Harvard
- Projet de sciences participatives / 47 sites d'études / 5920 h d'enregistrements
- Algo de reconnaissance auto genre BirdNET ? Avant de le faire, évaluation
- Mode "appât ornithologique" / les ornitho étaient invités à ""se battre entre eux"" ;)
- Aspect pédagogique pour apprendre à reconnaitre chants oiseaux
- Outil d'acquisition partiicpative de données
- Apprentissage pour IA
- Si expertise d'un utilisateur, ouverture du jeux de données (voir aspect licences / ouverture)
- Utilisation de Xeno canto https://xeno-canto.org/ dans phase de certification
- Volonté d'éavoir au moins 4 personnes ayant écouté chaque enregistrement . **Présentation des sites avec enregistrements par lus par 4 sur une carte**.
- **Pas de spectrogrammes sur interface pour le moment**
- **Pas de financements pour poursuivre développements sur le projet**
- C'était trop ambitieux au départ et il faudrait faire évoluer vers plus de participations
##### Question
- Yves Bas : Pourquoi 10 minutes d'enregistrement minimum ? Eux étaient partis sur 5 minutes pour leur projet d'annotation et petit a petit ils réduisent à 1 minute.
- Calibrer pour propres besoins, orienté "expert" (pas à destination grand public)
- Maxime : Cela doit frustrer un peu les gens le fait de sélectionner des experts. Intéressant d'avoir un pool d"'experts de référence est top, mais se priver de mains d'oeuvres supplémentaire.
- La phase de certification peut se faire plusieurs fois MAIS demande bcp de motivation !
- Maxime : bcp de participants ?
- Non, 20 enregistrements au total / pas suffisamment de participation.... Dommage car passé pas mal de temps au développement. Des financements avaient été cherchés pour améliorer.
- Maxime : Côté diffusion / publicité ?
- Contact direct d'ornithologues internationaux + qques uns "du coin".
- Pierre (retext de Plant Net) : ajuster les besoins chercheurs versus besoins/envies des participants
- Barrière de limitation de nombre d'experts. Passer des données connues de temps en temps pour classer les experts de façon masquée sans avoir à paseer l'étape de certiffication.
#### Pres.3 : Deepfaune par Simon
Deux projets
- **Deepfaune** https://www.deepfaune.cnrs.fr/
- Développer modèle IA pour mise à disposition de la communauté de recherche en aggrégeant les données des communautés.
- remettre à dispisition ces données annotées aux communuatés
- Tous le monde utilises des outils / approches différentes pour annoter les données, ici, ils ont utilisés tout (résultats zooniverse / foichiers excel, ...) => Ils n'ont pas annotés eux-même
- format Camtrap dp utilisé https://camtrap-dp.tdwg.org/
- **Le logiciel qu'ils ont développé permet notamment de passer derrière les modèles IA pour corriger / affiner** PAs de raccourci clavier and co donc pas forcémenrt le meilleur outil pour faire cela.
- Logiciel fonctionne en local
- LEs gens intègrent le plus souvent les modèles à leurs données, en ligne (?? pas sûr d'avoir bien noté)
- **Wehear** https://wildlabs.net/inventory/products/wehear-logger
- Capteur acoustique sur animaux
- Comportement
- Annotation pour développer modèles.
- Problématiques : données audio + innertielles et pas d'outil connu pour faire **annotation sur données multi modales**. Inertielles via Firetail https://www.firetail.io/ / Audio via audacity.
- **Des fois ils ont ce qu'il faut pour bosser en local, MAIS dès qu'ils veulent collaborer, c'est le bordel. Voir qui a fait quoi en temps réél par exemple...**
##### Questions
- Deepfaune : modèles entrainés sur combien d'images en moyenne ? Mix de plusieurs jeux de données OU entrainement sur un seul jeu de données
- Tous les jeux de données sont mélangés.
- Plus d'un millions d'images annotées conservés pour entrainement
- Enregistrements audio, il y a des traitements sur les capteurs pour mieux voir comment mobiliser les données ?
- Non car comme embarqué sur animal, pb de consommation ++ donc pas embarquer traitement sur les capteurs. Ils ont testés avec des petits modèles, mais du coup pas top donc résultats bof... Ils ont les données et l'idée est de prendre le temps de revenir dessus pour mieux voir ce qui est ok ou pas.
- Pour données multimodales, peut être voir côté ecodatacube / données compilées à partir d'occurence de données via raster. Structuration de données de différents types => Voir pour projet européen B Cubed https://b-cubed.eu/
- Questionnement sur mise en place solution commerciale ?
- En réflexion et au cas par cas pour le moment.
- Capteurs acoustique embarqué, comment ils récupèrent les données
- Récupération colliers / drop out (??) qui pose quesiton car "juste" poser collier pour 2 mois seulement pas top.
#### Pres.4: One Forest Vision Inititive par Hugo Magaldi
- platefome OFVi https://www.oneforestvision.org/
- suivi carbon / biodiv bassin africains et amazoniens
- PAs bcp de besoins d'annotation MAIS plus développements d'algo et fournir une interface / **Besoin : interface pour déployer sur le terrain (pas forcément de connexion internet / peu de gpu..) nos algorithmes de reconnaissance d'espèces et d'individus pour ofvi**
- camera traps / capteurs acoustiques / drones => Approche multimodale à termes
- Tri auto des espèces + identification des individus
- Avoir **méthodes standardisées** pour être réplicables / comparbale sur bassin du Congo
- **Commentaire perso Yvan => Lien GEO BON / GBiOS**
- Classificateurs inter espèces pour le moment en V1.
- **Interface = LE GROS BESOIN**
- Utilisation des modèles pour inférence.
- Modèle en Python donc il faut interfacve qui accepte cet environnement Python
- Il faut utilisation sur le terrain (PC portable sans GPU, sans Internet, user friendly)
- Voir EcoAssist de Peter van lunteren (https://github.com/PetervanLunteren) pour inspiration https://addaxdatascience.com/ecoassist/
- Vidéos en local, choix du modèle, liste référentiel espèce (cocher les espèces présentes) et résultats avec sortie CSV et visuel sur détections faites pour potentiellement pouvoir corriger.
##### Questions
- PAs de modèles développés ?
- Si si !
- Yvan: pourquoi ne pas utliser ecoASSist ?
- Elles sont très bien les fonctionnalités ! Il faut donc "juste" une plateforme FR. MUtualiser une plateforme avec les autres piliers scientifiques du OFVi DONC plut^tot pouvoir intégrer des solutions existantes MAIS il faut interface belle / unifiée pour "tout public" !
- Yvan : Déploiement local sans internet pose quesiton car Gaia Data / Data TErra met en place des outils et services en lignes. Il faudrait donc là imaginer d'encapsuler ces outils/Services dans une "boite" genre "valise Gaia Data"
- Point très important !
- Ici il y a des premiers tests en région ou il y a un peu internet qui permettrait de faire des premiers tests ""plus simple""
- **Stockage local possible et mise en réseau une fois par semaine par exemple pour synchro**
- Il y a aussi l'importance de devoir synchroniser les données locales vers une plateforme mutualisée pour sauvegarde long terme and co !
- **Il faut workflow simple permettant de réintégrer les données locales en distancielles**
- **Pose quesiton des aspects partage des données et licence !**
- Besoins particuliers d'intégrer différents languages ?
- A priori non, Python est ok
- temsp de transformeur en local pose pb ?
- Peut prendre du temps.
- Image transformeur / 3 images par seconde sur pc classique pour DeepFaune. **Megadetector est extrêmement lent (une image par 3 secondes)**
- OFvi et Sabrina / Hugo demande si ils sont les seuls à se poser la question d'une plateforme commune ? **Car il serait mieux de mutualiser les outils et de ne pas siloter les données entre mégafaune et autre...**
- **Cela rejoint les questionnements avec Terra Forma et SOL**
- Côté OFVi il y a un budget "plateforme" dédié.
#### Pres.5: Consortium Sounds of Life par Joséphine Simmonot
https://consortium-sol.huma-num.fr/
- constat : pas d'outils adpaté sur les plateformes institutinnnels sur les aspects "sons / acoustiques" notamment
- collecte
- archivage
- analyse
- etc..
- les pbs évoqués ont tjs les mêmes (pérénités, utiles)
- Enjeux : Dispo des données à tous pour avoir base commune. Données visibles incitent les gens à s'impliquer + aspect collaboratif
- Consortium financé par Huma-Num (IR sciences sociales)
- Objets très divers, des ambiances sonores et chauves souris
*obj* : 1) développer un outil (plateforme de dépôt) et 2) pouvoir analyser les données stockées
- **Interface de dépôt** en cours de développement => problématique de financement pérenne / Demande côté humanum - DataTerra. Data Terra pas prêt niveau logistique / opérationnelle et volonté politique d'agir sur sauvegarde de la biodiv donc il faut trouver la bonne stratégie plutôt que d'avoir les financements. Infrastructure de dépôt pas encore actée, prototype de l'interface de dépôt déployé via une maquette.
- Premiers développements via sous traitant habitué à ce genre d'outils. Gestion des profils, des accès, créer esapces de travail, partager ou non sa base de données, paramétrer son compte, ....
- Budget permettant de mutualiser les dépenses pour que cela réponde au maximum des gens.
- Puis plateforme de visualisation / analyse si possible grand public. LEs communautés seront invités à utiliser / partager leurs retours et besoins. Volonté de faire tourner des algo.
- Exemple de la plateforme du [CREM](https://archives.crem-cnrs.fr/) (échomusicologie) avec outil de traitement de fichiers audio accessible via le web
- Problématique de mobilisation des communautés (surtout si on ne rémunère pas les contributions) donc il faut rendre service !
- Faire proposition de data paper / technical paper
- https://github.com/Parisson/TimeSide algo pour génération des spectres de manière automatique.
- Il y a aussi consortium [CANEVAS](https://canevas.hypotheses.org/) pour stockage et annotation vidéo (SHS)
##### Questions
- Quel budget pour interface de dépôt ? Dépôt uniquement des fichiers sons ou aussi autres médias possible / pertinent ?
- Budget consortium env. 60-70K / an . aspect plateforme env 30K
- Côté infra, ce serait CC-IN2P3 potentiellement
- Pour autres médias (images, vidéos) il faudrait voir si opportunité de mutualiser.
- Pourquoi via HumaNum ? car expérience en annotation sons lors d'enquête ou autre ?
- Solution from scratch ? benchmark ?
- Sur Nakala le son est très basique, sur Hal pas adapté
- Quid de la métadonnée ? Schéma de métadonnées stnéadardisé (comme utilisé par Kevin - ecosound-web).
- Compatibilité Darwin core prévu pour envoyer à GBIF.
- Voir NOAA et métadonnées APLOSE
#### Pres.6: GBIF : caméra-trap, par Sophie Pamerlon
https://www.gbif.org/composition/4fZGV2vrXjo3rNxySz41sj/exploring-camera-trap-data
- extensions "simple media" et "audiovisual media description" https://rs.gbif.org/extensions.html
- Camtrap DP (https://biss.pensoft.net/article/73188/ & https://camtrap-dp.tdwg.org/)
- Dévellopé par Peter desmet
- Modèle et format pour échanger données de camera trap. Capture de données et métadonnées essentielles
- Logiciels
- Agouti / trap per / eMammal / Wildlife Insights
- Modèle en 3 tables :
- deployments.csv
- media.csv
- observations.csv
- Build on frictionless standards via JSON pour décrire data package / data resource / schema de table https://specs.frictionlessdata.io//
- camtraptor https://github.com/inbo/camtraptor
- Implémentation dans IPT pas facile mais fait ! A tester pour le moment !
- Exemple Data package avec métadonnées en EML décrivant fichiers sons https://search.dataone.org/view/doi%3A10.18739%2FA2SD4Z
##### Questions
- Il y a forvcément toujours un média accessible lié à une occurence taggué "vidéo" ou autre média ?
- le GBIF peut donc stocker des fichiers de type médias (sons/images) en quantité ?
- pour l'instant le GBIF ne stock ce type de fichiers en tant que tel, ce sont les producteurs qui le font, mais il y a des réfléxions en interne pour cette question qui va arriver rapidement.
#### Pres.7: ecoSound-web par Kevin Darras
- https://ecosound-web.de/ecosound_web/
- Publi: https://f1000research.com/articles/9-1224/v3
- autres activités: Acoustique et caméra à vision embarquée, entrainement de modèles IA pour bryophytes et insectes
- ecoSound-web créé il y a 10 ans pour analyser données ramenées d'Indonésie (où terrain) en Allemagne (où recherche)
- Fonctionalités en PAM
- Liens WOPAM https://www.wo-pam.com/ (PAM) et WWSS https://www.biorxiv.org/content/10.1101/2024.04.10.588860v1.full qui se base sur métadonnées
- Voir architecture d'avenir pour ecoSound-web pour réusiner
- Commentaire Yvan => Proposer déjà une partie des fonctionnalités via Galaxy après modularisation ?
- Flexible workflows ! Pouvoir faire différents workflows à partir de la catégorisation présentée en slide 2 !
##### Questions
- existe t il une version que n'importe qui peut installer ?
- oui via GitHUb
- Yvan : notions d'atomization et généralisation (cf. Galaxy) pour une plus grande flexibilité ?
- oui tout à fait
- refactorisation. Quel techno attendue ?
- En tant que non programmeurs, on avait du PHP et de plus en plus de javascript et maintenant, quand un nouvel ingé arrive, il prend de plus en plus de temps pour s'approprier l'environnement et permettre d'y ajouter des nouvelle sfonctionnalités.
- Pas de REST aPI, ni déploiement aisé en local....
- Il faut une plateforme qui puisse être gérable, par des structures diverses et variées !
- Volonté d'avoir données distribuées, pas de centralisation (comme SoL).
- Budget ?
- Via PEPR FOREST en acoustique passive où Kevin lead
- **TO-DO Yvan : Voir pour use case Gaia Data "PAM" Kevin en lien avec Christian Pichot**
#### Pres.8: Gaia Data et Data Terra par Olivier et Yvan
Yvan : https://docs.google.com/presentation/d/1RLfkPEr6G0khwHmlaIu8R4pfPMIptpR6uqPhjqr5708/edit#slide=id.g3166200b658_0_10
- Gaia Data = plateforme integrée numerique regroupant plusieurs briques, duree de vie de 7 ans https://www.gaia-data.org/contexte-enjeux/en-bref/
- Data Terra = https://www.data-terra.org/ infrastructure numerique regroupant les données du systeme terre (atmosphere, biodiv, geo) à longue durée de vie, end données FAIR (Facile à trouver, Accessible, Intéropérable, Réutilisable)
- CLIMERI = similaire pour les données Climat
- Analyse des données complexes
- Flux et stocks de {méta}donnees (issues de politiques publiques, inventaires national, projets de recherches)
Projet structurant la recherche, normalisation, aujourd'hui flux artisanal à date.
note : flux de données : "Comprendre, partager, ré-utiliser les données de
biodiversité" https://mnhn.hal.science/mnhn-04296424/document
- Presentation infrastructure Gaia Data
- Standardiser par la données ou la metadonnée ?
- Comprendre les données par la metadonnée par quelques principes.
- aspect VRE / annotation
- https://ecology.usegalaxy.eu/
- training https://training.galaxyproject.org/training-material/topics/ecology/
##### Questions
- Quid stockage / archivage des donnees : discussion sur bandes magnetiques (pas cher, pas facile d'acces, pas de garantie) ou archivage officiel cher, autres solutions locales. questions ouvertes
- Travail sur la conversion d'un standard à un autre mais aujourd'hui pas de solution satisfaisante ==> contacter les producteurs de données
#### Pres.9: Maxime Equipex+ Terra Forma
https://docs.google.com/presentation/d/1V5In4MBw2MkOswtZulqIi5pFRHsRW0WRR1y7wzebjyg/edit?usp=sharing
- Intéractions biotiques-abiotiques
- développements de capteurs avec visée frugale
- Phase de construction jusque 2026 et phase d'exploitation ensuite jusque 2028 pour mise en place de capteurs sur Zones ateliers
- Plusieurs suivis en WP2 dont biodiv
- Biodiv acoustique via enregistreur audio intelligent
- Suivi non destructif des arthropodes
- Entomoscope pour remplacer recéptacle piège malaise avec alcool donc destructif)
- Buzzureur
- WP4 = création plateforme
- Du capteur à l'action / Utiliser au mieux les interactions humains IA pour accélérer et standardiser l'identification de données de biodiv
- Test d'outils existants
- CVAT pour la vision / https://github.com/cvat-ai/cvat
- Avec **CVAT ils ont galéré à faire pré annotation par IA. Plein de fonctionnalités trop cool MAIS trop complexe pour étudiants**. Ils ont fait interface custom pour pré-annotation
- Annotation audio exhaustive (tous les sons sont annotés) faite par 2 personnes (Elodie MAssol et David Funosas) via audacity. Lien projet PSIBIOM.
##### Questions
- la plateforme annotation est dédié WP2.8 "biodiv" ou tous capteurs ?
- CVAT utilisé en local ? intérét à avoir instance partagée ? En mode standalone ou serveur ?
- En mode serveur. Il y a une IA utilisable pour pré annoter MAIS ils ont pas la main dessus (car hébergé par TOULOUSE ?)
- Interface custom pour pré-annotation réutilisable ? Intérêt à mettre à dispo par Galaxy ? En mode standalone ou serveur ?
- Standalone déployé via un JSON sur Raspberry Pi
- Pour audio, intérêt à partager les données via Galaxy ? Annotation possible par des experts ?
- **Il faut qualité du spectrogramme / réactivité ++ pour des experts notamment (hard label) ! Par contre, pour non expert, proposer du "soft label"** Si on coupe plus cours que 1 minute, problèmes car manque de contexte !
- insectes vivants pris sur fonds uniformes, intérêt à utiliser des échantillons numérisés ? Comme ils ont fait côté plantnet avec herbier.
- Oui, ils ont scraper GBIF rapidement pour cela.
- **Lien potentiel recolnat / erecolnat**
- Voir potentielle réutilisation ARISE de Naturalis https://www.naturalis.nl/en/science/arise-knowing-nature-in-the-netherlands car proche. Voir pour utilisation API
#### Pres.10: Catherine Borremans Ocean spy
https://ocean-spy.ifremer.fr/
Compter les espèces mobiles ou calculer les surfaces par exemple
Pb de volumétrie de données acquises nécessitant aide pour traiter les images acquises.
Depuis 2017, deep sea spy, et depuis année dernière ocean spy => impliquer les citoyens pour le traitement des données
Ocean Spy = plateforme d'annot SP, parametrable, nb de vues, especes...
Chaque projet est administré par le chercheurs.
Avoir approche plus transversale. Méthodes de prétraitement et de validation des données (adaptation du package R ""deeptools"" (https://github.com/Deep-Sea-Spy/deeptools )
Communication pour implication public, associations, implementation des modele IA ==> jeux de donnees propres. Annotations suffisantes pour entrainement
Perspectives et besoins d'automatistion, Mise en ouvre d'IA pour analys eet traitement auto, retour aux citoyens
##### Questions
- Quel nombre de participants ? Le fait de multiplier les nombres de projets ne divisent pas le nombre de participation ?
- Pas forcément, en tous cas manque de recul.
- Nombre d'annotations par mois ou par jour ? 4000 à 5000 participants qui ont fait au moins une participation mais pas d'infos plus détaillés.
- Il y avait eu envie de passer par zooniverse mais projet pas retenu.
- Design bien fait pour communication et pour le grand public ! Mais pour un projet comme cela, pas le choix ! On transfert le coût de production de données vers un coût de traitement via engagement d'acteurs humains externes. Quel mécanisme incitatif ? Quel reward / retour le contributeur cherche ? Implication des enfants peut aider à toucher les parents.
- **Commentaire Yvan : Lien vigie nature école**
- Oui mais pas de volonté de multiplier le nombre de protocoles
- Quel budget ?
- Développement de départ : **50k€ design et dev web pour deep sea spy**
- Puis par tranches de 5k€
#### Pres.11: Pierre Bonnet PlantNet
https://docs.google.com/presentation/d/1Be5jlPHox1hfDPRlYnIhkteHN9HYyr_L47Nu-cZAXR8/edit?usp=sharing
One forest vision / GUARDEN / MAMBO / PlantAgroEco
Cooperative learning for biodiv monitoring
Il y a des choix antérieurs assumés à ne pas remetter en cause, mais c'est vrai que des nouveaux venus peuvent remettre en cause, il faut expliquer et pouvoir justifier.
200 pays / 53 000 espèces / 7 millions d'utilisateurs / 200 000 à 2 millions d'identifications par jour . 1,2 milliard de requpêtes d'identification (mais malheureusement pas la moitié géolocalisée) / 24 Millions observations partagées / 11 Millions d'observation valides. Une fois le côté "lien social" mis en place il a fallu cadrer la diversité des applications and co.
Modèle IA réentrainé tous les 3 mois pour limiter l'impact environnemental et équilibrer la mise à jour de nos modèles avec les attentes des participants et les couts en ingénierie.
Problème accès web fait que compliqué **pour rendre utilisable hors ligne de l'app PlantNet, cela a prisplusieurs années pour finaliser cet accès hors-ligne** Et au final, en proportion peu de gens utilise cette version hors ligne, cependant elle a pour but de soutenir un usage précis / contexte précis important pour les objectifs globaux. Il y a une sycnhronisation auto auto donc aspect hors ligne pas pour tous les utilisateurs.
Il y a des gens qui utilisent sans compte (>2/3), d'autres avec (<1/3).
Diversification des usages.
CC-BY-SA peut être un frein pour certaines institutions qui préfèrent CC-BY-NC
Curation des données partagées au GBIF, pour éviter d'envoyer des données d'espèces jamais découverte dans une zone ou les données de POWO ne l'ont jamais recensée avant.
A chaque fois, ils refont détermination avec dernier modèle IA avant envoi dans GBIF.
Parmis les plus gros data provider to GBIF.
720 M => 12M pour données envoyées au GBIF par anonymous
12 => 1,8 M pour données envoyées au GBIF par personnes avec un compte.
Diversification :
- Outils collaboratif / notion de groupes / pages d'utilisateurs / messagerie
##### Questions
- Redétermination par dernier modèle IA est cela qui est fait tous les 6 mois ? Avant envoi dans GBIF ?
- Plateforme = 60 serveurs et 4 infra différentes (CIRAD / INRAE / INRIA et Jean Zay).
- S'il devait s'y reprendre aujourd'hui, ils feraient peut être différemment. Choix fait à la base sur ratio coût / service qui sont plus les mêmes. 400 To de stockage aujourd'hui moins cher que avant au To. Le fait d'utiliser différents sites, permet de s'appuyer sur les capacités de chacun d'eux, et est optimisé par RENATER ! Donc hébergement des images là où c'est le moins cher (ici MesoLR / Univ Montpellier).
- Retour d'expérience PN possible mais difficile à généraliser car bcp de projets différents sont présentés aujourd'hui et le contexte est différent aujourd'hui par rapport à nos choix passés.
- P. Bonnet est content d'ici prendre connaissance des contextes pour les problématiques aujourd'hui et pour les choix faits / à faire / à assumer
- Yves : EN plus, sur autres taxons, inaturalist indétronable pour du très grands publiques, donc il faut voir selon les besoins particuliers qu'on a côté recherche !
- **Commentaire perso Yvan : Il faut peut-être considérer une plateforme à deux niveaux selon qu'on vise des scientifiques vs du grand public ????**
- **Yves : Il y a un grand gradient entre grand public et scientifiques !**
- Pierre : Il faut se poser des questions sur quel espace on peut prendre quand on créait une plateforme ? Réflexion pour être dans la complémentarité pour investissements rentables.
#### Pres.12: Yves Bas SPIPOLL
Clef d'identification non dichotomique. Partenariat avec asso OPIE
Validation collaborative. 4532 observateurs / 200 qui font 90% des observzations ! 767 405 photos / 1472 835 validation
Utilisation IA pour voir si jeu de données permet de donner bonnes perf. Via ResNet192, cela fonctionne bien sur certaines étapes. **Peut-être qu'on a pas tant besoin d'IA pour reconnaitre des espèces mais plus pour améliorer les résultats** par approches complémentaires (ciblages insectes / prise en compte des métadonnées / prise en compte hiérarchie taxonomique). **Comment intégrer l'algo SANS pénaliser les progrès des utilisateurs !** Les gens sont devenus super bons en reconaissance et il faut pas casser cet aspect apprentissage ! Notamment du grand public !
- Vraie question de l'utilsiation plus vertueuse que d'autres de l'IA. Peut-être ne pas les opposer !
##### Questions
#### Pres.13 : Yves Bas Vigie Chiro et Tadarida
Vigie-Nature 20 programme de SP / Vigie chiro depuis 2006 (chauve-souris / sauterelles...)
Programme SP à destiantion des naturalistes pour suivre tendances des pop selon protocoles standardisés
Couverture spatiale assez hétérogène en protocole pedestre et routier mais bien réparti pour point fix ! Un peu pus de 20 000 nuits d'enregistrement par an.
Acoustique passive par open harware ou dispositifs commerciaux.
Données envoyées via u portail sur CC-IN2P3 puis identification par Tadarida, Bilan automatique puis interface de validation peu développée et dont moins en moins d'usage.
Dans Tadarida, il y a outil d'annotation avec points d'énergie de cris de chauve souris. 20 000 chunks de 5 secondes annotés pour ensuite entrainer les premiers algo. Ils utilisent toujours l'outil pour sauterelles et chauve souris. SInon pour audible and co, comme oiseaux, **ils ont abandonné cette interface. Interface d'annotation de sonogrammes ok pour sauterelles et chauve souris, pas ok pour oiseaux**.
Distribution des score de détection par nuit renseigne sur le fait que ce soit faux positif ou non?
Chirosurf 2.3 développé par un contributeur (Yann Trévilly) pour visualiser spectrogrzamme and co et permet d'avoir plus d'infos plus vite et de plus de personnes !
Vol de nuit
- Avec trektellen (donées de tracking au niveau europe) et biophonia pour matériel.
- Besoin de plus de métadonnées et intérêt de suivi matériel
- Les personnes annotent à la main en passant une heure par nuit. PAuline teste l'utilisation d'algo IA. On risque ceci dit d'arriver sur pblématique comme spipoll qui voudra pas d'utilisation de IA MAIS posibilité de toucher plus de monde
- IA pour toucher plus de monde / pas d'IA pour naturaliste.
Projet Leko / Birdz / suivi 100% auto !
Pour le moment, dans vigie-chiro surtout frequence pour chiro et sauterelles et volonté de voir autres espèces comme grenouille et hiboux car outils exsitnats maintenant pour tester !
Pour annotation, ils sont parti de structrue de données de l'équipe de MAxime et ils ont du tordre le protocole d'annotation car déjà ils ne voulaient pas être exhaustif sur chunk de 1 minute quand très dense (Mais toutes les espéces sont annotés juste une seule fois) + faire en sorte que les box soient exclusifs (est-ce que une seule espèce dans une box). Cela pose pb quand plusieurs espèces si on doit changer de segmenteur ! **Donc ici ils ont focalisé sur non exhaustif MAIs exclusive !** Possibilité de ne pas être très carré sur box SI on a suffisamment d'hétérogénéité dansl es données.
Les algos de machine learning random forest aussi abandonné en arrivant sur audible (champ d'oiseaux) et là les réseaux de neurones profonds mieux !
Données d'apprentissage ok pour oiseaux mais limité hors oiseaux MAIS possibilité de fine tuner différents modèles pour BirdNET par exemple, qui est très rapide, importnat notamment si bcp d'heures à annoter !!! Surement plus important de se concentrer sur phases amont (avoir jeux de données de qualité) et pas aval (classifieur débile à résoudre via info contextuelle)
**=> Plutôt que de vouloir recréer des modèles, partir de modèles existants pour faire fine tuning !**
En télédetection bcp de classification contextuelle, il y a la même problématique avec les capteurs ! Un environnement sonore à un moment donné, va être impacté par contexte !
17% de comptes confidentiel, mais le reste en open data.
Côté SINP, ils ne donnent pas les 800 Millions de données qu'ils ont en validation auto - MAIS dans SINP pas moyen de filtrer les résultats sur critère de confiance ! Donc ils ne fournissent plus que ce qui est vélidé par humain !
Il suffit de qques données de capteurs mauvaises pour décrédibiliser les sources de données et les plateformes pas prêtes à partager des résultats d'IA.
- **Il aimerait bien une interface web qui permet aux utilisateurs de flagguer les données comme douteuse et que ces données puissent être filtrés dans la suite voir éliminées !**
- Côté collaboratif de flag serait top
25k€ par an pour Amazon S3 pour passage des données vers CC-IN2P3 !
##### Questions
- Si on veut du contexte, c'est pas contradictoire avec la volonté de limiter les tailles des sonogrammes ?
- Non mais il vaut mioeux avoir un classifieur dédié à la detection de cet aspect "contexte"
- **Proposer 2 approches complémentaires, une pour classifier les événments et l'autre sur bande plus large pour avoir le contexte**
- Il y a des manières d'améliorer les perfs notamment via tehcno de bdd. Vous utilisez quoi ?
- Mongodb / nosql.
#### Pres.14 : Dorian Cazau OSMOSE
https://docs.google.com/presentation/d/1O0qdub0z13sm9-oqy5Xa3DO5EEqOYT1f7qd8FYrV7mI/edit#slide=id.g3147129c1eb_0_37
Open Science meets Ocean Sound Explorers
Ocean Sound Essential Ocean Variable / 3 piliers scientifiques du GOOS / Ocean health / Climate change / Monitoring Threats
**=> Liens EBVS et GBiOS !**
=> Volonté de contribuer à ARGO par acoustique
https://archimer.ifremer.fr/doc/00855/96688/
Codes sources sur GitHub https://github.com/Project-OSmOSE
Jupyter notebook https://github.com/Project-OSmOSE/datarmor-toolkit/tree/main/notebooks
https://patternradio.withgoogle.com/
Se retrouve bien dans le bilan fait par Yves sur le fait que côté IA cela va trop vite côté plateofmre et du coup il vaut mieux se positionner vers human in the loop / annotation...
- test https://osmose.ifremer.fr/app/
- Question de recherche côté variabilité inter annotateur
- Galaxy history pour test jupyter notebooks ! https://ecology.usegalaxy.eu/u/ylebras/h/sound-explorer-osmose
https://osmose.ensta-bretagne.fr/
--------------------------------------------------
**journée 2 (20/11/24)**
#### Pres.15 : Ocapi, par Julien Ricard (Terroïko)
https://www.terroiko.fr/fr
Ocapi observation de la biodiv par des CApteurs Plus Intelligents
Transfert de technologie de la science vers industrie.
Besoin : Données de capteurs brutes (images pour le moment, audio à venir) -> Ocapi -> données naturalistes normalisées (qui peut être utilisées pour 2-3 projets qui peuvent interopérés via standards au moins nationaux) /
- Utilisation commerciale
- Serveur cloud CPU / GPU + stockage
- Annotation collaborative (distribution des annotations + robustesse)
- GEstion des la confidentialité des données
- Intégration de modèle IA custom
- Taxonomie TAXREF
- Intéropérabilité avec nos outils internes + standards nationaux : SINP en particuliers occtax (et Geonature bdd très utilisée chez bureaux d'études donc dev API prévu)
- export JSON et données brutes images
A venir / utilisation taxo GBIF / audio / améliorer UX/UI pour accélérer et faciliter annotation / amélioration des modèles IA génériques + intégration de modèles spécialisés / licence AGPL MAIS pour le moment pas de diffusion du ciode car ils veulent finaliser le code propre avant.
OCapi a une 100aine d'utilisateurs.
Cas d'usage PSI-BIOM : entrainement d'IA
- Gestion du risque de collision avec ls grands ongulés (analyse données visuelles)
- Suivi efficacité écologique des pratiques et structures agroécologiques (Audio)
- OCAPI intervient pour récupérer la donnée (stockage / pré traitement / annotation / export) PUIS entrainement d'IAs et embarquement des IA dans les capteurs pour IA offline
- Utilisation outil Ecological Engineering Studio (gestion capteurs / traitement / analyse / jumeaux numérique / reporting SIG)
##### Questions
- normalisées vs standardisés ?
- affichage en fonction du score de confiance ? Pour faire active learning par exemple. C'est notament pour la gestion en batch. Deepfaune par exemple est bon pour identification auto et on peut utiliser scores.
- Non, car volonté de faire un ratio ergonomie / fonctionnalités.
- Yves : En fait c'est aussi que les utilisateurs n'ont pas l'habitude d'utiliser un score de confiance (idem vigie-chiro il y a 10 ans).
- pour IA utilisation prévue de l'approche hiérarchique ? Quelle piste (par noeud / par feature ...)? L'idée fait que cela devrait fonctionner, MAIS au final la classification hiérarchique n'apporte pas grand chose pour le moment vu comment c'est implémenter. Classification hiérarchique permet d'intégrer données taxonomiques dans apprentissage.
- Très exploratoire. Poir le moment ils vont prédire les feuilles (noeuds les plus fin) pour ensuite prédire les niveaux supérieurs.
- Bcp de gens ici ont fait développé leurs softs par des prestations. On est utilisateur et on a pas la capacité de développer des outils pérennes and co. Développement Ocapi fait en interne, mais ajout d'élément pas évident. C'est quoi le business model derrière ? La direction va laisser l'outil aux scientifiques qui pourront s'en emparer / ajouter des choses. Les chercheurs pourront ajoutés des features eux-mêmes.
- Vendre du processeur / GPU / Stockage
- Ils veulent faire API simple pour ajouter modèles et pré traitement.
- **Il faudrait faire une grille de ce qu'il faut pour un outil pour qu'il soit utilisé / via Galaxy ou autre notamment.**
- dans le pourquoi OCAPI, le premier est le côté utilisation commerciale.
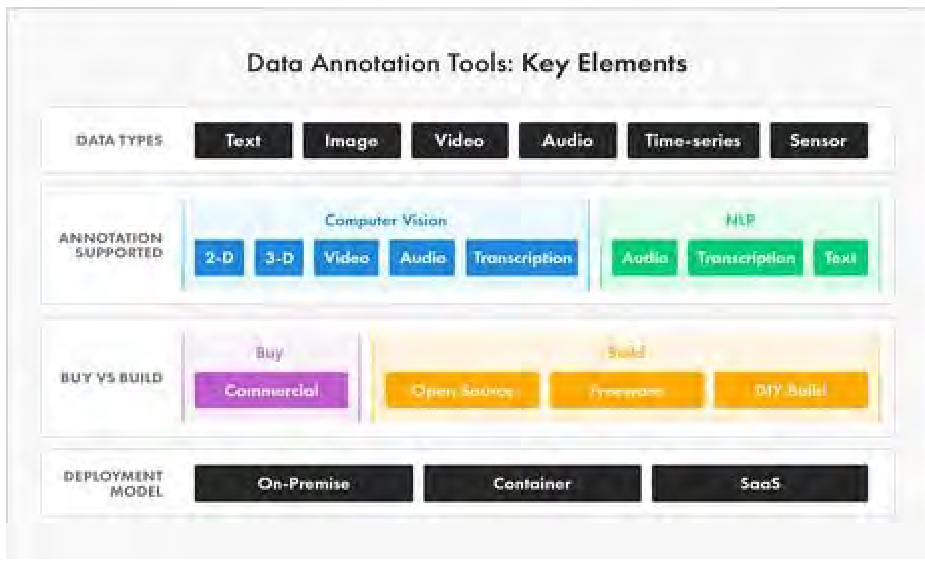
## Atelier 1 : Catalogues de logiciels d'annotation audio/photo
Flux de travail / catégorisation fonctionnalités SAP - Suivi Acoustic Passif (PAM)
- Data management
- Signal processing
- Visualisation et navigation
- Acoustic Analysis
Objectif initial : Quels sont les catégories et est-ce qu'on est d'accord sur notion de flux de travail + tenter de classer dans même catégorisation audio ET photo.
- **Objectif revu : La liste des fonctionnaités pour logiciels audio est aussi pertinente pour les logiciels images ? OU c'est quoi les fonctionnalités communes et les spécifiques**
Quelle tâche d'annotation on veut ?
- Segmentation
- ROI
- ...
- **=> Ajouter fonctionnalité "planification des tâches d'annotation"**
Il y a aussi l'**aspect séquentiel des tâches d'annotation** à mettre en avant. Le moment où on planifie les tâches n'est pas les mêmes que quand on est en train d'annoter et d'autres fonctionnalités après la campagne d'annotation. **Concept BeDurAf**
- Before annotation
- During annotation
- After annotation
=> ET des fonctionnalités peuvent se retrouver dans plusieurs étapes (before/during)
=> Julien Ricard : ICi il me manque entrée et sortie.
- Effectivement, si on parle de flux de travail, il y a entrée et sortie
- **Il y a un travail pour aller vers flux de travail depuis une catégorisation !**
1. Est-ce qu'on arrive à être ok sur une classification commune PUIS mettre les outils en face
2. Est-ce qu'on peut proposer des flux de travails pertinent => peut-être pour l'atelier “FAIRiser” les briques logicielles sélectionnées & pertinentes
Côté marine image annotation tool, il y a déjà un listing existant https://www.sciencedirect.com/science/article/abs/pii/S0079661116301240 mais côté sound, c'est pas le cas. Travail en cours par collègue de Kevin (Tara). 245 outils utilisés dans PAM. Remplir la case annotation dans le fichier.
Réfléchir aux différentes manières de représenter les type d'annotation.
Images
- detection and contouring
- identification / classification
- Measurements
- => of organisms/habitats/objets
Mesures = annotation ?
Standardisation des méthodes ...sémantique
- Annotation faible (xeno canto) et forte, concept commun audio et images. On pourrait en fait classer les images !
- **Il faut faire plsuieurs tâches différentes pour les données de capteurs (pas que une) avec mélange petits dataset "strong" et gros datasets "weak"**
- weak label ne permet pas de faire co-occurences d'espèces ! Voir exemple de birdNet.
- Aspect temporel lié à son, pas trop image SAUF si on est dans le cadre de la vidéo !
Annotation en 2D ok.. mais intérêt de l'annotation en 3D ou multiD ?
- Quelle utilité ?
- Peut-être pour filtrer sur certains critères
- Pour représenter image + son + vidéo ?
- Pour avoir info géographique + temporel
- Pour aspect vidéo
- Notion du contexte temporel
- Notion du multimodel / multicapteurs. Est-ce que ce serait util d'annoter vidéo + audio en parallèle ?
- Le support d'annotation pour l'audio seul. On a hérité de l'utilisation du spectrogramme mais cela pourrait être différent genre multispectrogrammes.
- avoir des annotations sur la fréquence et le temps est utile
Tests outils
- CVAT => très customisable MAIS bcp de choses, trop et donc orienté scientifique !
- Avoir un catalogue des outils et/ou classification des outils dans panneau outil Galaxy avec labels correspondant (acquisition/data type/analyses)
- Interface maison rapide / pas trop de fonctionnalités. JSON avec labels. Que bounding box
- Pour préannotation. Affichage infos taxonomique à gauche.
- Code mis sur raspberry pi
- **Pouvoir sélectionner en amont les fonctionnalités qu'on veut pour donner accès aux outils pertinents. Proposer un arbre de décision aux PI de projets d'annotations qui leur permettrait de choisir au final les "briques" logicielles pertinentes constitutives d'un VRE dédié au pojet (un sous domaine Galaxy ?)**
- Aspect persistence des annotations vs persistence des outils (mode serveur vs standalone SaaS)
- Si standalone SaaS (comme audio labeler), alors récupération des annotations dans un ficchier, du coup voir pour partager / centraliser les annotations dans bdd commune.
- **Test Biigle montre capacités d'export et doc mieux que cvat ! Semble être un outil qui fait consensus** Voir avec Viame, comparatif Viame / Biigle : https://www.ign.fr/publications-de-l-ign/institut/kiosque/etudes/etude_labellisation_ign_2021.pdf
- Biigle party (pour sciences participatives) en cours de dev
- future ajout d'une fenetre temporalité absolue + localisation (tracé GPS) de la campagne du bateau
- ajout de la fonctionnalité MAIA https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0207498
### Classification commune
- Ajout de pré annotation dans "acoustic anlaysis" car utilisé en image processing, pas sur audio MAIS intéressant/pertinent d'avoir cela sur son aussi !
- Faut-il séparer humain et automatique ? Pour mieux voir liens entre les deux ! IA vs boites à la main par exemple
### Workflows / Flux de travail
- Il faut identifier les tâches
- On peut partir d'un son et voir ce que les gens vont en faire.
### Questions
- Outil existant pour représenter des catégories and co de manière de faire cahier des charges...
- Mindmap ?
Outils faisant consensus
- Annotation image/vidéo => Biigle/Viame voire CVAT (mais jugé moins bien / plus complexe)
- Annotation acoustique =>
## Atelier 2 : Citizen empowerment / Expérience utilisateur
**question 1 : comment permettre aux novices de r"aliser des identifications difficiles et de monter en compétences?**




**question 2 : comment envisavez-vous les interractions IA / Humains?**


**question 3 : quelles sont les adaptations nécessaires aux différents publics (SP, recherche, pro/privé...)?**

**question 4 : comment intéresser le grand public?**




=> idée de storytelling (en entrée pour décrire les projets d'annotation) + de création de "data paper" à la fin des annotations pour que l'utulisateur reparte avec un "rapport" de son travail.
=> idée must have "à la galaxy bricks" de pouvoir proposer à l'utilisateur de créer son projet de refcherche, sa question de recherche.
**to do : synthèse des éléments à garder ou pas via questionnaire à envoyer à nos réseux respectifs (terra forma, gaia data)
## Atelier 3 : “FAIRiser” les briques logicielles sélectionnées & pertinentes
- retext sur un outil comme galaxy peut aider à la FAIRisation, creation des workflows pour justement "atomiser" et sélectionner les étapes "importantes" (= briques)
- cf. projet [EBVOSC](https://www.pndb.fr/fr/activites/projets-techniques-et-scientifiques/ebvosc) + cf [Royaux et al 2024](https://ecoevorxiv.org/repository/view/6965/)
- **Classical unatomised script**
- **Atomised script**
- **Atomised workflow**
- **Atomised and generalised workflow with modular steps**
- **Building generalised workflows from open, modular and licenced anamytical steps**
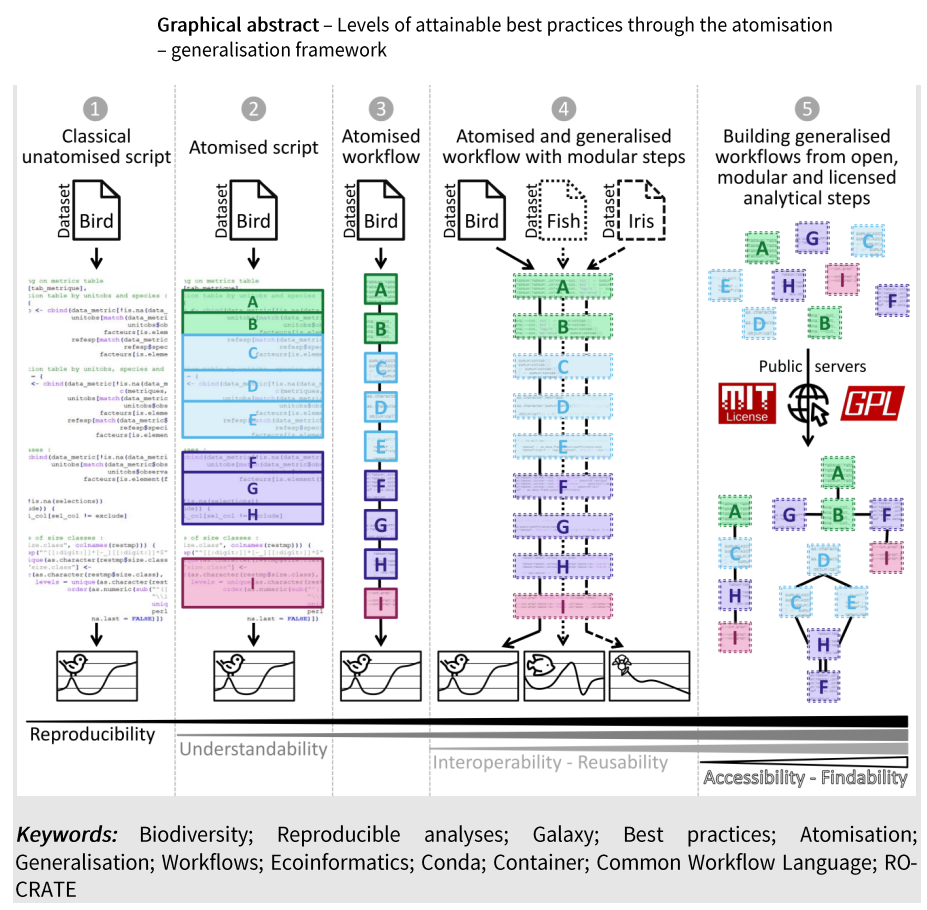
- les questions qu'on doit se poser :
- qu'est ce qui peut être généralisaeable ou pas ?
- qu'est ce qui peut être spécifique ou pas ?
- IFDO
- exemple de Galaxy Bricks https://www.vigienature-ecole.fr/bricks
- 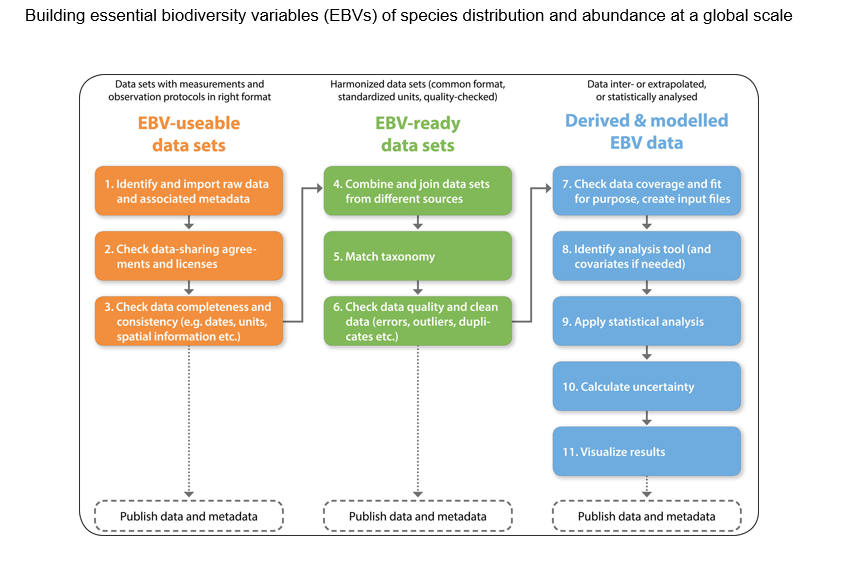
- from [Kissling et al 2017](https://onlinelibrary.wiley.com/doi/10.1111/brv.12359)*Workflow steps of key relevance for building Essential Biodiversity Variable (EBV) data sets for species distributions and abundances. The workflow steps are grouped into three major types of EBV data sets (see Fig. 1): EBV-useable data sets (orange), EBV-ready data sets (green) and derived and modelled EBV data (blue). Each of the EBV data sets should ideally be published with relevant metadata.*
- **use case à tester par Dorian**
- création d'une instance ou vue d'une instance Galaxy dédiée annotation car désormais possibilité de développer le "front end"
### questions
- est-ce réellement transposaable à l'anotation ?
- faut tester, cela a été fait avec les EBVs car cela "se présente bien"
- pouvoir préparer via une API la pateforme d'annotaiton avec du code
## récap journées 1 et 2
### session 1 (matinée)** :
- diversité d'outils
- besoins similaires
- concepts similaires (sémantique) entre domaines marin/terrestre/son/image
=> **possiblitlité d'avor une réflexion commune / globale**
### session 2 (atelier caractérisation)**
**objectif** : Sur la base d'une revue sur les logiciels écoacoustiques et les logiciels d’annotation d’images:
- Nous comparerons les flux de données des données acoustiques et images **oui, aspect séquenciel**
- Une catégorisation de fonctionnalités de logiciels pour l'annotation audio et photo sera présentée et discutée. **oui**
- Nous déterminerons quelles méta-données enregistrer pour les annotations des différents types de médias.**oui DwC, EML, IFDO**
- Les participants évalueront les fonctionnalités des logiciels avec les médias enregistrés lors de la sortie de terrain. **oui et non car démo**
**ce qui a été fait**
- liste et classification des étapes de gestion/traitement de données média permet déjà d'avoir une base commune d'échange entre acoutique et image/vidéo, pour ensuite être réutilisée pour proposer liste d'outils et lien avec workflows.
- flux de travail "gros grain" commun selon un aspect séquenciel "before/during/after" annotation qui permet d'envisager une entrée de plateforme et/ou des listing d'outils dédiés
**ce qui devrait/pourrait se faire**
- mettre un stagiaire/CDD sur revue de litérature sur les outils d'annotation d'image (benchmarking)
- tester de mapper les métadonnées avec les standards existants (DwC audiovisual, EML, IFDO) et voir pour réutiliser cela pour classifier les outils et/ou permettre de les utiliser pour la plaetforme
- voir ce qui est transféreable de l'audio vers l'image (car à priori les produits image sont bcp similaires donc plus facile de partir d'une base commune)
### session 3 (utilisateur)
**ce qui a été fait**
**ce qui devrait/pourrait se faire**
Besoins Terra Forma et OFVi on voit synergies / entre SOL et PEPR FOREST on voit synergies, MAIS entre Terra FORma - OFVi et SOL - PEPR FOREST ? Est-ce qu'on veut faire une plateforme qui fait les 2 (son et images) ?
**Proposition de scénarios**
- **Intégration de briques logicielles pertinentes pour mise à disposition via plateforme Galaxy**
- Investissement dans ocean spy pour mise open source et réutilisation ?
- Investissement dans MAJ ecosound-web (réusinage prévu mais pas avant 2025) et/ou APLOSE
- Voir ecotaxa et intérêt à l'utiliser / y contribuer
- Voir ecoAssist repéré pour faire le boulot coté OFVI
- Pour déploiement "offline", envisager "Galaxy dans une valise" => un serveur local sur pc boosté utilisable sur le terrain
- Galaxysation des briques logicielles "asynchrone" (notamment créer outils Galaxy équivalent à "workflow" ecoassist) et "interactive/synchrones" (CVAT/Biigle/Viame/APLOSE => Pour ce type d'outils interactif, voir si utilisation en mode SaaS / déploiement à la demande pertinent + s'il faut proposer une version en mode serveur)
- **Chaque projet développe son truc from scratch sans liens (développement de novo)**
- inconvénient : coût projet en parallèle, contre productif niveau comunnautés
- avantage : chaque projet a exactement ce qu'il veut
- plateforme d'accompagnement / formation, qui dirige vers un catalogue de solutions adaptées, une vue Galaxy etc...
- avatanges : chacun peut devepper un aspect "briques" de cette platefromre sans que ce soit "compliqué" niveau admin/RH/$
**Points de vigilance particuliers sur usage de Galaxy**
- Le problème majeur est le côté interface graphique / expérience utilsiateur. Si de gros développements ont été faits pour rendre Galaxy plus ergonomique et customisable côté interface graphique / expérience utilisateur, la plateforme impose une interface unique qui n'est pas des plus simples, surtout pour des publics hors scientifiques.
- On peut tout de même noter que Galaxy est déjà utilisé par des publics hors recherche dans le cadre de projets de sciences participatives notamment (Vigie chiro et champs de bloc OFB en France / Projets avec collégiens en Allemagne) et par des bureaux d'études.
- L'utilisation de Galaxy permet d'utiliser une interface unique/commune pour l'ensemble des outils nécessaires.
- Un budget pourrait être dédié à l'amélioration de l'ergonomie de Galaxy, notament pour un usage "simplifié" par un public non expert.
- Point de vigilance sur les aspects volumétrie des données. Aujourd'hui, en utilisant Galaxy Ecolog Europe, chaque utilisateur dispose de 250Go d'espace de stockage. Est-ce ok ou problématique ?
- Pour remédier à cela, il faut déjà identifier si de gros volume de données pourraient être partagés plutôt que utilisés par utilisateur, notamment au sein d'un espace partagé de données de référence, comme c'est fait dans Galaxy pour les données de génomes par exemple. Ensuite, si c'est un frein, cela peut amener à mettre en avant l'intérêt de déployer une instance Galaxy dédiée Gaia Data / Terraforma / OFVI avec customisation des droits et quotas.
penser en scénarios en mode word café
scénarios 1:
----
## Journée 3
### Matin : Echanges bilan / résumé en lien avec objectifs opérationnels
#### Aspect infrastructure derrière les logiciels
SOL va réussir à faire un endroit où déposer des sons, et où on peut lancer des pipelines IA dessus. Mais ce que SOL ne fera pas a priori, c'est une plateforme d'annotation comme révée durant les échanges de ecoinfoFAIR.
=> être moins ambitieux sur les aspects "branchement IA" et se focaliser surtout sur "annotation".
On veut annoter sur pré traitement IA, mais prétraitement IA peut être à la charge de l'utilisateur !
Qu'est-ce qu'il y aura dans SOL qu'il n'y a pas autre part (entrepôt de données + DOI + envoi vers GBIF).
Normalement il y avait idée de mettre infrastructure logicielle, mais il y a eu incident diplomatique.
=> Y a-t-il des capacités de stockage côté SOL / humanum ?
=> SoL va être sur entrepôt, donc on peut les laisser faire et on verra bien, on se focalise sur autre.
=> Voir pour que le périmètre passe à l'audiovisuel ! (Kevin: j'en doute. Peut-être quand le consortium sera prolongé?)
=> Il y a des besoins en stockage pour données froides (ce que fait SOL)! Et aussi données chaudes (??Equipex+?? COMMONS - Gaia Data)!
- Côté esapce chaud, problème de limitation de volume !
**Retour de doctorant (Edgar) : Pas envie de perdre du temps, donc plutôt une plateforme unique / mutualisée qui centralise tout.
=> c'est la question la plus importante / la plus structurante : veut on / y aura t-il une plateforme pour plusieurs média ? Il y a beaucoup de liens entre les flux de travail entre images et sons donc c'est pertinent ! Enormément de recouvrement !**
Tout est atomisé, il n'y a plus qu'a mettre ensemble ! Chaque outil à sa gestion des utlisateurs, son backend et compagnie et c'est redondant !
- Déconstruire les logiciels / atomes et reconstruire en commun. Idée de réusinage ecosound.
Importance particulière de stocker et conserver les données brutes ! Car intérêt de réanalyse !
**Constitution de bases de données d'apprentissage**= peut-être le bon terme à utiliser plutôt que de parler média ou annotation...
- PAs que média, mais aussi données associées, métadonnées / infos
Problème de volumétrie. Des centaines de To générées, mais on annotera jamais des centaines de To. Il faut flagguer auto les données qui vont rester sur du chaud et celles qui vont aller dans du froid ! Il y a aura même pas 1% de données sur espace chaud.
- **consommation de calcul vigie-chiro n'est pas montrueuse MAIS demande de la RH / ingénierie pour dev et analyse. Ils savent intégrer données brutes, faire tourner pipeline IA, et à partir de cela ils savent que c'est possible de qualifier l'intérêt de la donnée car chacun à son script pour faire active learning (?) et donc telle donnée est plus intéressante à être annotée que d'autre. Il faut échantillonnage stratifié de ces données là !**
- Il faudrait outil permettant de ventiller ces données à la volée pour avoir 20% de données dans données chaudes sur un exemple de tapis roulant qui permet de refroidir une partie et d'en avoir de nouvelles en chaud rapidement.
- **Liens avec Mésonet** https://www.mesonet.fr/2_le-projet.html ?
- **TO-DO Yvan voit a vec Gaia DAta et Mesonet**
- pour imagerie marine aux US ils sont en train de faire un truc comme cela (fathomnet https://fathomnet.org/).
#### Aspect logiciel
- Mettre les idées et faire tourner les prestations. Pour cela il faut des serveurs / endroits où mettre les services qui vont être développés pour conrétiser les discussions commune image et son de ces jours ecoinfoFAIR. PAr exemple pour passer Vigie-chiro sur de l'audible (oiseaxu)
- Il y a des possibilités côté Terra Forma, côté INRAE, côté BBEES-CC-IN2P3 (exemple pour migratline et Anaïs). Le frein principal est plus sur les projets type sciences participatives sur lesquels on ne sait pas combien de données vont être traitées.
- **Possibilité de faire tourner des calculs / traitements via linux sur les données MAIS pas de plateformes d'annotation and co.**
- **MAIS ils sont en train de voir pour prestation pour avoir interface de dépôt de données sons de vigie-chiro directement sur CC-IN2P3**, chose possible aujourd'hui mais qui n'était pas possible en 2018.
- **Il y a problématique de dépôt de données par le web ?**
- Oui, pour images comme pour sons, donc potentiel intérêt de réutiliser l'outil de dépôt vigie-chiro par terra-forma and co.
- Des développements sont prévus, idem pour ecosound-web => besoin de réusinage récurrent ! MAIS pour dev "one shot", après, personne pour la maintenance !
- Quels outils ?
- ecoSound-web ? Ou voir pour autres solutions parmi la revue faite pour voir ce qui est le plus durable.
- Dans le domaine audio, ecoSound-web semble bien complète
- Whombat https://arxiv.org/abs/2308.12688 ?
- APLOSE ?
- Une différence : ecoSound-web et Whombat permettent de gérer le côté taille des fichiers en faisant des calucls et affichages à la volée sur fenêtre audio (pas chargement de l'entièreté du fichier comme APLOSE)
- Intérêt ecosound-web : accès possible à données distantes via SFTP en faisant "tampon" donc en chargeant que ce qui est nécessaire
- Volonté de faire une fédération de serveurs ecoSound-web via API notamment pour échanger les métadonnées de toutes instances.
- Il y aurait plutôt un ecosound-web déployé pou terra forma sur serveur dédié côté Terra Forma.
- Mais entrainement pas faisable via ecosound-web, il faut faire cela à part.
- il faudra travailler sur des tutos dédiés d'identification ! LPO travaille bcp là-dessus !
- **Google pattern radio** = google maps pour annotation audio https://patternradio.withgoogle.com/ & https://medium.com/@alexanderchen/pattern-radio-whale-songs-242c692fff60
- ecoSound-web pourrait aussi être utilisé pour les images / profiter du réusinage pour ajouter cela
- Idée qui a émergé était de connecter toutes les briques audio et images/vidéos via Galaxy par exemple MAIS en fait, il y a aussi possibilité de rassembler tous les médias ""à un endroit"" / via une plateforme ""ecosoundweb"" surlaquelle les utilisateurs pourraient choisir mode citoyen ou scientifique puis les outils (ecosoundweb / cvat / biigle / viame / ...).
- Fusionner gestion utilisateur et bdd avec ecosound-web.
- **Tabler sur deux axes**
- **Un axe "Gaia Data" via Galaxy avec interface générique Galaxy**
- Mais possibilité de bénéficier du portail de découverte / des protails thématique le cas échéant pour faire entrée dédiée
- **Permet d'accompagner et animer les échanges / réflexion sur atomisation / généralisation et aspects workflows !**
- Poursuivre les échanges à travers un / des documents en attirant les communautés (OFVi, PEPR, Freiburg, Vogelwarte (CH)...)
- Permet d'avoir outils Galaxy classiques dédiés pour certaines étapes des workflows (conversion des formats de label csv vers heaven / audacity / gbif and co) et autres outils de type interactif avec possibilité de passer par API pour usage via service externe (par exemple ecosoundweb réusiné).
- Permet d'avancer sur FAIRisation des process orienté média
- Permet de capitaliser sur l'ensemble des devs
- **Un axe ecoSound-web pour tout faire avec interface dédié audiovisuel**
- Et posibilité de choisir entre expert vs citoyen pour interface particulière
- Capitaliser sur les 20k€ prévu dans PEPR FOREST pour réusinage ecosound-web + argent Terra Forma pour élargir à aspect images/Vidéos
- Risques car pas que bounding box entre sons et images ! Il y a segmentation and co
- Proposer que la future version de ecoSound-web (audiovisualweb?) devienne une plateforme de gestion des données communes audio et visuelles / média et annotations et qu'on connecte des lecteurs / visualisateurs dédiés aux différents types de média (CVAT, Biigle, APLOSE...).
- Cela nécessite de spécifier les standards de données de chaque brique
- Peut intéresser OFVi car réusinage ecosoundweb notamment pour utilisation offline par utilisateurs africains avec ecoassist
- Si OFVi (ou autre PEPR/projet comme FORESTT) intéressé, peut-être que ofvi peut permettre de faire vivre l'outil via animation autour de la plateforme !
- CVAT pose pb (certains déjà mentionnés jours précédents) notamment sur import/export labels / métadonnées pas vraiment standardisés...
- Idée d'arriver sur un cahier des charges détaillé et de le soumettre aux différents "partenaires ecoinfoFAIR" et voir qui répond / comment.
- Aspect meilleure gestion de taxonomie
- via taxref / IUCN / GBIF / ...
- Il faut a minima référencer la base de référence et la version pour a priori pouvoir faire les liens de cohérence a posteriori
#### TO DO
##### Gaia Data
Il me semble se dégager ainsi deux actions principales, la première en déclenchant potentiellement plusieurs autres :
- Mettre en place une task force / un groupe de travail ~"Gestion et traitement des données de type média" liant personnes côté VRE Data Terra / Gaia Data (Yvan & autre(s) ?) et infra (Karim ? Rémi ?) et personnes métiers (en partant de ceux qui étaient là cette semaine et qui représentaient déjà pas mal la communauté via IFREMER, CNRS, INRAE, MNHN, IRD, OFB) dont Terra Forma, Maxime en copie, pour avancer sur aspects FAIRisation et sélection des briques logicielles et possibilités côté infrastructures/sites/architecture.Ceci permettrait :
- La mise en place d’une animation dédiée “audiovisuel” initiée pendant ecoinfoFAIR2024
- De nourrir les travaux opérationnels à faire et proposer des scénarios de mutualisation
- Côté WP3.3 VRE Galaxy action 3 “annotation” (liens use case WP5 / PEPR FORESTT…)
- Côté développement de plateformes Terra Forma et OFVi.
- => Il est proposé que ce travail se base sur la création d’un nouveau composant de la tâche WP4.5 Gaia Data “atelier FAIR” dédié à la FAIRisation des codes sources biodiv/système-terre/climat via approches de standardisation mises en avant via WP2.7 et WP3.3 Gaia Data en proposant de partir de l’approche atomisation/généralisation proposée dans le cadre de Galaxy Ecology (Coline Royaux et al 2024 https://doi.org/10.32942/X2G033) qui permet de partir des expertises en analyses existantes dans le domaine pour créer des “briques/atomes” de traitement de données à haut degré de FAIRitude, réutilisable largement, notamment ici via VRE Gaia Data (Galaxy) et des plateformes (Terra Forma / OFVi). Cette approche se base en plus sur des aspects “techniques” présentés dans Grüning et al 2018 (https://doi.org/10.1016/j.cels.2018.03.014) avec un focus workflow de traitement de données en lien avec variables essentielles (Kissling et al 2018 https://doi.org/10.1111/brv.12359).
- Faire lien inter equipex+ Gaia Data - COMMONS (via la task force / le gt mentionné ci-dessus ?) sur la question et pour articulation avec initiative SOL et mise en place entrepôt média, pour le moment orienté “son” côté SOL / Humanum.
Un point d'attention qui avait été soulevé déjà lors de nos échanges en coordination de WP2/WP3 en janvier, et que j'avais rappelé lorsque le Bureau exécutif Gaia Data de février avait mis en avant l'importance de mettre dans plan de développement WP3.3 cette action "gestion et traitement de média", est que a priori cette action ne concerne pas CLIMERI. Suite aux échanges de cette semaine, il m'est apparu (je ne suis pas du tout expert de ce domaine) que des approches scientifiques pouvaient utiliser par exemple des données d’acoustique passive pour produire des informations de type force du vent and co, aussi je me demande s'il ne faut pas creuser cette question ""utilisation de média pour le climat""...
## Update 2025
### TO DO Terra-Forma / FORESTT Monitor / OFVi
- Mise en place échanges mutualisation à partir de ecosoundweb, proposition de schéma de cible par Maxime ci-dessous
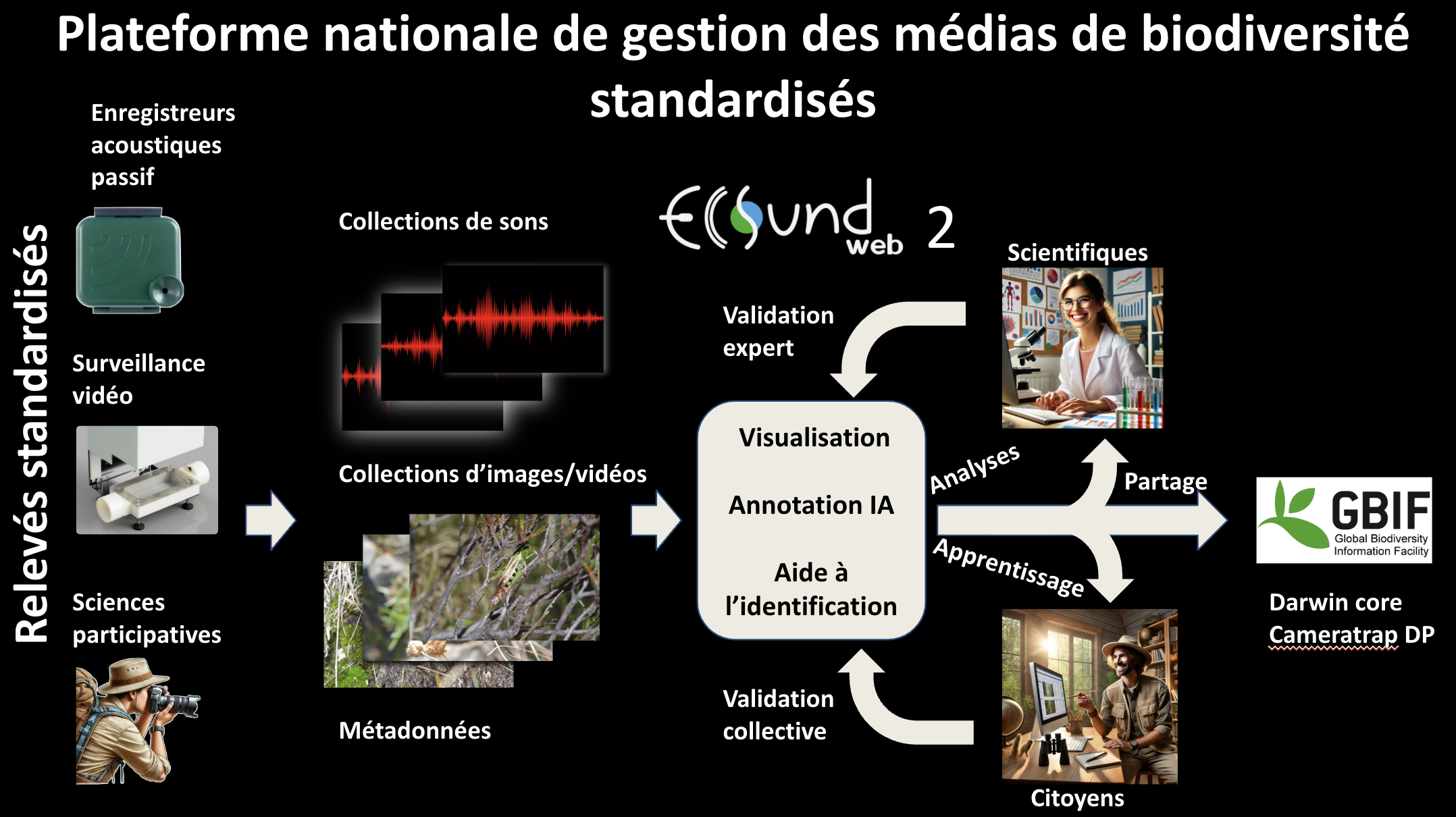
- Réunion d'échanges prévue en février 2025
### TO DO Gaia Data
- Mettre en place une task force / un groupe de travail ~"Gestion et traitement des données de type média" liant personnes côté VRE Data Terra / Gaia Data (Yvan & autre(s) ?) et infra (Karim ? Rémi ?) et personnes métiers (en partant de ceux qui étaient là cette semaine et qui représentaient déjà pas mal la communauté via IFREMER, CNRS, INRAE, MNHN, IRD, OFB) dont Terra Forma, Maxime en copie, pour avancer sur aspects FAIRisation et sélection des briques logicielles et possibilités côté infrastructures/sites/architecture. Ceci permettrait :
- La mise en place d’une animation dédiée “audiovisuel” initiée pendant ecoinfoFAIR2024
- De nourrir les travaux opérationnels à faire et proposer des scénarios de mutualisation
- Côté WP3.3 VRE Galaxy action 3 “annotation” (liens use case WP5 / PEPR FORESTT…)
- Côté développement de plateformes Terra Forma et OFVi. **=> Voir [TO-DO Terra-Forma / FORESTT Monitor / OFVi](https://codimd.math.cnrs.fr/MIFuxmu1R1Gh5zh5gUlvZQ?both#TO-DO-Terra-Forma--FORESTT-Monitor--OFVi)**
- => Il est proposé que ce travail se base sur la création d’un nouveau composant de la tâche WP4.5 Gaia Data “atelier FAIR” dédié à la FAIRisation des codes sources biodiv/système-terre/climat via approches de standardisation mises en avant via WP2.7 et WP3.3 Gaia Data en proposant de partir de l’approche atomisation/généralisation proposée dans le cadre de Galaxy Ecology (Coline Royaux et al 2024 https://doi.org/10.32942/X2G033) qui permet de partir des expertises en analyses existantes dans le domaine pour créer des “briques/atomes” de traitement de données à haut degré de FAIRitude, réutilisable largement, notamment ici via VRE Gaia Data (Galaxy) et des plateformes (Terra Forma / OFVi). Cette approche se base en plus sur des aspects “techniques” présentés dans Grüning et al 2018 (https://doi.org/10.1016/j.cels.2018.03.014) avec un focus workflow de traitement de données en lien avec variables essentielles (Kissling et al 2018 https://doi.org/10.1111/brv.12359).
- Faire lien inter equipex+ Gaia Data - COMMONS (via la task force / le gt mentionné ci-dessus ?) sur la question et pour articulation avec initiative SOL et mise en place entrepôt média, pour le moment orienté “son” côté SOL / Humanum.
- Faire valider ces aspects utualisation par tutelles CNRS/IFREMER/IRD/INRAE/MNHN
Un point d'attention qui avait été soulevé déjà lors de nos échanges en coordination de WP2/WP3 en janvier, et que j'avais rappelé lorsque le Bureau exécutif Gaia Data de février avait mis en avant l'importance de mettre dans plan de développement WP3.3 cette action "gestion et traitement de média", est que a priori cette action ne concerne pas CLIMERI. Suite aux échanges de cette semaine, il m'est apparu (je ne suis pas du tout expert de ce domaine) que des approches scientifiques pouvaient utiliser par exemple des données d’acoustique passive pour produire des informations de type force du vent and co, aussi je me demande s'il ne faut pas creuser cette question ""utilisation de média pour le climat""...
## Après midi Formation Git/GitHub/Rcompendium
https://frbcesab.github.io/intro-git
https://frbcesab.github.io/good-practices
https://github.com/frbcesab/rcompendium
Et un exercice de la formation Reproductibilité qui explique pas à pas un bon research compendium : https://rdatatoolbox.github.io/chapters/ex-compendium.html
https://choosealicense.com/
----
### TO DO annexes
- Revoir Zooniverse / Mise à disposition des images
- Réfléchir au temps d'enregistrement audio à mettre à dispo pour annotation / plage de temps sur laquel on met un label
- Arriver à faire publicité / amener du monde, est un problème récurrent ! Comment toucher le plus de monde ? Ratio masse / qualité à bien regarder selon questions. Trouver le bénéfice que peut y trouver le participant. Etre proactif aux réponses aux attentes avant de collecter les données.
- Ethique de la science participative / équilibre entre intérêt du chercheur vs du participant. Lien vision de la nature and co qui évolue avec les années.
- Voir package R ""deeptools"" https://github.com/Deep-Sea-Spy/deeptools
- Liens outils / données !
- les changements d'échelle pour la collaboration (local/en ligne) (experts/citoyens)
- Voir annotation de données multicapteurs / multimodales (innertielle + acoustique par exemple en synchro)
- Voir si approche ecodatacube du projet B Cubed https://b-cubed.eu/ peut aider
- Voir si transformer les données inertielles en données "acoustique" (ou l'inverse) peut être pertinent pour utiliser le même outil ?
- Problématiques qui **n'intéresse pas forcément bcp de monde côté multimodal MAIS oui pour multicapteurs** avec besoin de colocalisation.
- Audio permet de valider l'inertiel.
- **=> SUJET à discuter : Comment prendre cet aspect colocalisation et multicapteur en compte pour l'annotation ?**
- boite à outils "Gaia Data / Data terra" pour du local/on line
- droits des données
- OFVi
- Quels sont les besoins des autres piliers scientifiques côté plateforme ? Car ici, Sabrina et Hugo sont sur pilier biodiv et carbone.
- Faut-il une solution de sauvegarde des données sons FR ou xeno canto ok ?
- flux et stock des données (chaudes/froides) et calcul/traitement (rapprocher le calcul des données et pas l'inverse)
- Créer des data packages Camtrap DP et tester l'utilisation de IPT pour envoi à GBIF
- Tester échanges métadonnées entre les différents systèmes (aplose and co)
- Voir pour atomiser / généraliser les briques logicielles ecosound-web pour notamment permettre d'avoir flexibilité / workflows à façon
- **Traiter différemment expert (hard label) et non expert / la foule (soft label)**
- Revenir vers Dorian pour aspect variables essentielles / EBVs / EOVs et opérationalisation via soundscape.
- **Difficile de préconiser des choix ! Il faut en faire et les assumer !**
Aspect stratégie développement logiciel / aspect
**=> Plutôt que de vouloir recréer des modèles, partir de modèles existants pour faire fine tuning !**
**Proposer 2 approches complémentaires, une pour classifier les événments et l'autre sur bande plus large pour avoir le contexte**
- **Voir pour initier réflexion EBV sur sound observation / Dorian Cazau**
- Voir pour test jupyter notebook dans Galaxy.
**Il faudrait faire une grille de ce qu'il faut pour un outil pour qu'il soit utilisé / via Galaxy ou autre notamment.**
**Commentaire perso Yvan suite à échanges PlantNet : Il faut peut-être considérer une plateforme à deux niveaux selon qu'on vise des scientifiques vs du grand public ????**
Yves : Il y a un grand gradient entre grand public et scientifiques !
Pierre : Il faut se poser des questions sur **quel espace on peut prendre quand on créait une plateforme** ? **Réflexion pour être dans la complémentarité d'autres initiatives pour investissements rentables**.
**TO-DO Yvan : Voir pour use case Gaia Data "PAM" Kevin en lien avec Christian Pichot**
**TO-DO Yvan : Voir pour partage outils Galaxy yolo + outils traitement EBV à Maxime pour test par étudiants**
### Ressources
- https://github.com/zenml-io/awesome-open-data-annotation listing annotation tools / Open Source Data Annotation & Labeling Tools dont multimodal
- EcoAssist de Peter van lunteren (https://github.com/PetervanLunteren) https://addaxdatascience.com/ecoassist/
- Zooniverse (CREA Mont BLanc)
- Xeno canto https://xeno-canto.org/
- Réutilisation https://archives.crem-cnrs.fr/ pour plateforme audio ?
- Deepfaune https://www.deepfaune.cnrs.fr/
- Format fichier camera trap https://camtrap-dp.tdwg.org/
- CVAT pour images : https://www.cvat.ai/
- OCAPI de teoroiko pour sonogrammes https://www.terroiko.fr/fr/ocapi
- Exemple Data package avec métadonnées en EML décrivant fichiers sons https://search.dataone.org/view/doi%3A10.18739%2FA2SD4Z
- présentation audio labeler / NEAL+ R sHiny app https://github.com/gibbona1/audio_labeler
- openecoacoustic https://openecoacoustics.org/
- maad https://scikit-maad.github.io/sound.html
=> mention de ecotaxa
- https://www.sciencedirect.com/science/article/abs/pii/S0079661116301240 benchmark outils annotation image marine
- https://f1000research.com/articles/9-1224 ecoSound-web avec revue logiciels dedans
- Etat de l’art des outils existants permettant d’obtenir et saisir les données d’apprentissage dont comparatif Viame / Biigle : https://www.ign.fr/publications-de-l-ign/institut/kiosque/etudes/etude_labellisation_ign_2021.pdf
- plateforme canadienne images et sons https://wildtrax.ca/resources/user-guide/ et package R lié https://github.com/ABbiodiversity/wildRtrax
- Voir pour mutualisation Gaia Data Ifremer Ecotaxa + Biigle + campagne.
- Critères important pour évaluer outils de traitements de média
-